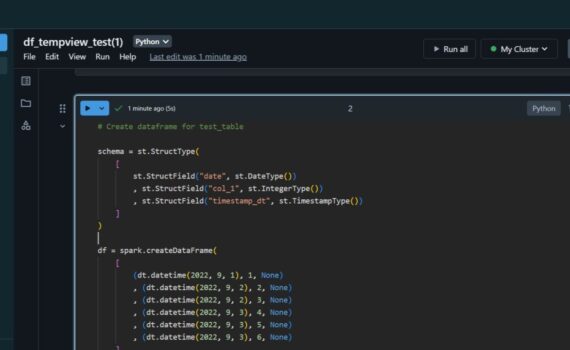
When we insert data into spark dataframe, it continues to live in the source (delta table). In this example i: Spark Dataframe Pandas Dataframe When we select data from delta table into pandas dataframe, the data is transferred to the dataframe. Keep it simple :-)
Azure
13 posts

When working with Azure Synapse Serverless, we store the data in Parquet Files, not in a database. These Parquet Files in Data Lake are external tables in the serverless database. One limitation related to the external tables exists – we can’t DML them, i.e. we can SELECT, but not INSERT […]
In this example i will facilely explain my logic to extract dynamically in Azure Data Factory or Azure Synapse from multiple servers and save the result in Azure Data Lake. This post extends the logic, explained earlier in another post – Azure Data Factory (ADF): Dynamic Extract Driven by SQL […]
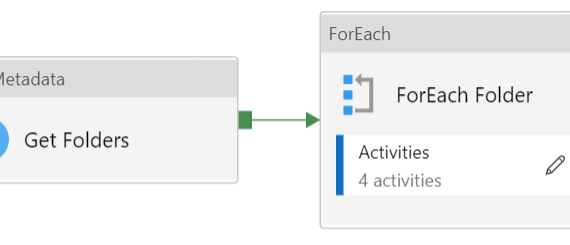
In some cases i need to loop folders and files in Azure Data Lake Storage in order to import data in the destination. The file structure can look like: That means that i need to loop this stricture with two nested ForEach Activities in ADF pipeline – one for the […]

Azure Synapse Analytics offers the so called “serverless” database. It keeps the data in .parquet files. One thing i was suspicious with was the data types in the .parquet file. I decided to test if they are all NVARCHAR(4000) or we can use the standard SQL Server data types. In […]

Download JupyterLab portable from portabledevapps.net: Install and start the app: Open in browser: Add PyPI: Add the code that i posted here and start the development: Related posts: Python: Build JSON Array and keep the last object based on key Keep it simple :-)

An ETL that i build recently instigated me to share the following excerpt of python code. The players in this ETL are: Apache Kafka (Source) Azure Data Factory (ETL app) Azure Databricks (Extract and Transform with Python) Azure Data Lake Storage (File storage) Cosmos DB (Destination) In this example i […]

This python code can be used to extract two files from Kafka in Azure Datalake (ADLS): extract/kafka/topic/topic_{YYYYMMDD_HHMMSS}.json – no duplicates (PK: parentId|id) extract/kafka/topic_history/topic_{YYYYMMDD_HHMMSS}.json – all the rows (PK: parentId|id|date_created) If case of error, the KafkaException is exported in a file with name error_topic_{YYYYMMDD_HHMMSS}.txt. ADF determines if there is an error, […]
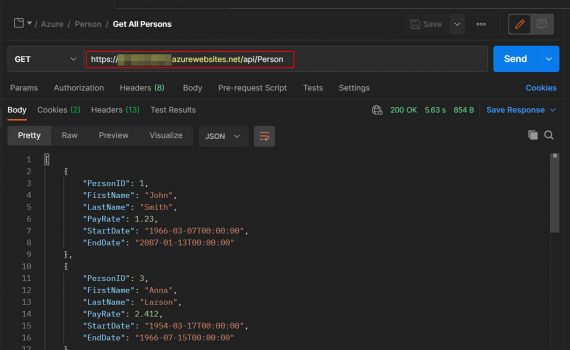
This example explains how to create REST API server. It could be deployed on-premises or in Azure (cloud). Technology used: Visual Studio 2019 (C# Windows Web App) SQL Server 2019 (on premises) Azure Authentication: Basic (base64 encoded Username:Password) Requests: HTTP SQL GET SELECT POST INSERT PUT UPDATE DELETE DELETE Database […]

In this example we create ADF pipeline that extracts from SQL Server and saves in CSV files in Data Lake. The point is just to demonstrate the logic so you can edit it as you need. The extract is driven by SQL Server table with all the parameters for a […]