
When working with Azure Synapse Serverless, we store the data in Parquet Files, not in a database. These Parquet Files in Data Lake are external tables in the serverless database. One limitation related to the external tables exists – we can’t DML them, i.e. we can SELECT, but not INSERT […]
Azure Synapse
4 posts
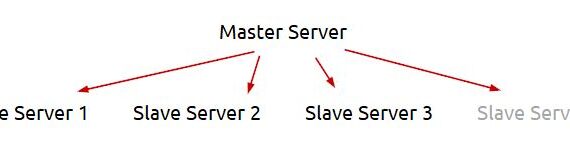
In this example i will facilely explain my logic to extract dynamically in Azure Data Factory or Azure Synapse from multiple servers and save the result in Azure Data Lake. This post extends the logic, explained earlier in another post – Azure Data Factory (ADF): Dynamic Extract Driven by SQL […]

Azure Synapse Analytics offers the so called “serverless” database. It keeps the data in .parquet files. One thing i was suspicious with was the data types in the .parquet file. I decided to test if they are all NVARCHAR(4000) or we can use the standard SQL Server data types. In […]

This python code can be used to extract two files from Kafka in Azure Datalake (ADLS): extract/kafka/topic/topic_{YYYYMMDD_HHMMSS}.json – no duplicates (PK: parentId|id) extract/kafka/topic_history/topic_{YYYYMMDD_HHMMSS}.json – all the rows (PK: parentId|id|date_created) If case of error, the KafkaException is exported in a file with name error_topic_{YYYYMMDD_HHMMSS}.txt. ADF determines if there is an error, […]